Just as you start off on a Monday morning, at 9:01am, there’s a page, that crucial, heavily used site is broken, users are blocked from working and frustrated. What went wrong?
There were staging and integration environments to protect production from untested application changes, there was comprehensive monitoring and alerting on staging and production, there were smoke tests! But even with all this in place, something was still missed…

A post-mortem follows, it appears as if a perfectly working piece of code breaks when simultaneously accessed by multiple users. The kind of thing you can only discover when you have a lot of *real* users?
Why load all the time?
The above scenario illustrates an often overlooked part of running a service, users. Smoke testing in a pre-production environment is useful, but far from a realistic test of a live service. What we need is to be able to simulate an active site, with multiple real user journeys through the service happening all the time. When something breaks in production, we want to be the ones to find it first, not have it alert us as it happens to a user. Or even better, let’s break it in staging first.
With this in mind, better to develop a strategy to improve digital services to help make them healthy, sustainable, and always there for end-users. The key things to look for are,
- Always have virtual users using services
- Have virtual users making journeys through sites as realistically as possible
- Have the number of virtual users constantly and randomly changing
Creating Virtual Users

The choice I made for the prototype of this ‘Continuous Load’ service was Tsung, an open-source multi-protocol distributed load testing tool. Tsung allows the scripting of advanced site usage, and the randomisation of those usages through the use of user session probabilities, meaning that effectively a dice is rolled to decide what kind of user our virtual user will be, and what they will try to do on our site. Also, Tsung is capable of heavy and distributed loading, which means we can scale up to many thousands of users accessing our sites simultaneously.
For more information on Tsung session configs and recording your own through the tsung proxy, see the]2 and recorder section.
The Prototype
The prototype loading service is based on MoJ Digitals Cloud Platform, an automated cloud stack and configuration provisioner. This provides simple and repeatable full-service creation, meaning that the end website is fully available. In order to have simple scheduling available without creating a more advanced setup, this was left up to a saltstack cron-formula, using random delays to add a bit of entropy to the loading schedule.
The general process is,
- Cron schedules a tsung container run, optionally with a random delay
- A URI to a tsung config file is passed into the tsung container on start
- The tsung container loads the config and begins its run
- As the run finishes, the results and graphs are backed up to S3
- The container terminates
At any one time, there will be multiple containers running, including on the same service if specified.
Scheduling load

As a first approximation of good loading, I aimed for,
- Low Level Usage: A few dozen users every minute
- Medium Level Usage: A few thousand users a minute
- High Level usage: A tens or hundreds of thousands of users a minute
The principle is to set a low level usage 24 hours a day. This means that there is a constant interaction of virtual users with the service, meaning that no matter what time of day, there’s a reasonable chance any bugs or service problems will be encountered by one of our virtual users first, perhaps giving us time to rectify the problem before any actual users have come across it.
In addition there’s a daily medium load lasting less than an hour, this load makes sure that our site behaves appropriately when we have thousands of users, real and virtual, using our site. This could happen in the middle of the night, or at peak usage times, meaning that our service needs to be robust enough to cope with a rapid, but realistic increase in demand.
Lastly, there is ‘high’ load. This loading is moving towards a full stress testing setup, with the kind of demand beyond that which we would expect to see on a service. This could be described as mirroring the ‘tweet effect’ on our site.
What It Looks Like
Here we have a constant low level of users arriving on our site, but also an hourly high load and random medium loading. The bar chart below shows the effect this has on our site request times.
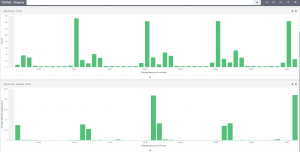
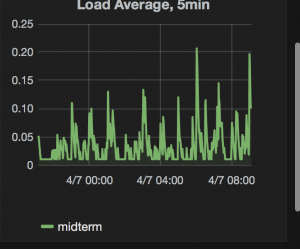
How do you know if it worked?

The goal of this approach is to simulate real life users on your site, making sure your site performs well under heavy use, and that journeys through the site end well for the user. So, how do we define success? Success is anything that proves the site works well for people, and anything that proves it doesn’t!
For example,
- The addition of thousands of virtual users at peak time didn’t harm the response times on the site, so the service is robust for fluctuating traffic.
- One of the virtual users journeys through the site triggered a 500 error, the alerting went off and created an incident! This is a good thing, the issue was discovered before any actual users hit the same problem.
Note that the benefits of loading the site depends heavily on,
- How realistic are the virtual users? Have we recorded/replayed realistic user journeys through our site? Do we have good ‘code-coverage’ with our less common pathways?
- Is our monitoring going to tell us when one of our virtual users have hit trouble? In the above simple example we’ve relied on http status codes and response times to alert us to problems, in other services we may need more refined alerting to be sure. As always, we look to alert on ‘is the user experience affected?’
Towards a Better User Experience
Overall, the use of continuously loading on sites with virtual users, from the earliest moments of project development to the live production servers, always generating real-life usage of our site even when none exists means that we can pro-actively push towards robust, sustainable services through constant iterative performance improvements.
In this way, we can truly build user experiences into our services.









